
Why Post-Deployment Adoption Fails in Odoo Projects and how to fix it.

We just returned from the Odoo Experience in Brussels with one big takeaway:
Every partner is grappling with the same issue - post-deployment adoption.
To manage it, most rely on frequent check-ins:
“We meet weekly, sometimes twice a week, and work through issues with the client.”
It’s a reasonable approach when the client is small and the team is just 10–20 people. You can talk to everyone directly. You can keep a mental model of who’s struggling, what flows they’re using, and where the friction is.
But once the client scales to 50, 100, or 300+ users, that model breaks.
Weekly calls + surveys don’t scale.
They’re time-consuming, biased, and reactive. And while several partners reminded us that adoption isn’t technically their responsibility (it’s not in the contract), they also admitted that if adoption lags, the customer won’t be happy - so they end up doing it anyway to ensure satisfaction and retention.
Partners are responsible for delivery, but they’re judged (rightly) on adoption, and there’s no reliable, proactive way to see what’s actually happening across the org between meetings.
The gap we kept hearing
“We do lots of meetings.”
Good for relationships, bad for time.
They’re not targeted at the right employees, and you end up guessing which module/section is the problem - so the real blockers stay hidden and the quiet issues still get missed.
Reality: most partners run weekly / fortnightly / monthly check-ins and only speak with the manager (they can’t afford 1:1s with 50-300 employees). The manager then summarizes adoption issues - but they’re not seeing usage firsthand, so it’s biased and incomplete. Lots of struggles go unreported.
“We run internal surveys.” Helpful, but slow to interpret, and often biased by who answers.
Hidden assumption: this only works if managers have a reliable intake system to collect struggles from their teams. Most don’t; it’s ad-hoc Slack threads, forms no one fills, and anecdotes.“We’re responsible for success, but blind to the day-to-day.” Partners only hear about issues after they get loud.
Retention is competitive. In a crowded partner market, proactive adoption is what keeps clients.
Why weekly calls and surveys don’t scale
Limited coverage: A 45-minute call can’t tell you what’s happening across hundreds of users and dozens of workflows. You hear the loudest voice, not the full picture.
High latency: By the time a problem makes it into a meeting, it’s already compounded. Friction becomes workaround. Confidence erodes. Recovery is slow.
Manager filters & bias: Most check-ins run through one person, usually a manager, who isn’t watching usage. So they summarize what they think is happening. That’s often off.
No precision: You don’t know who struggled or where. So you default to “invite everyone” training, not “train these 7 users on this exact step.”
Rising cost, shallow truth: Fortnightly calls across accounts burn time and rarely surface ground truth.
Reactive and guessy: Even if adoption isn’t your contractual responsibility, retention depends on it, so you’re on the hook, but flying blind.
What user analytics gives you instead
Breadth over anecdotes: See patterns across all users, not just whoever joined the call.
Precision: Spot the exact module, step, and cohort that’s struggling, and how badly.
Prioritization: Triage based on reach (sessions/users) and impact (roles, goals, revenue risk).
Fast, targeted fixes: Decide if it’s a bug, a UX flaw, or a training issue, and act accordingly.
Proactive motion: Quiet failures like hesitation, loops, or workarounds don’t rely on someone speaking up. You spot and solve before they escalate.
What “good” looks like
To get a better understanding of adoption within Oodoo, you need a simple, repeatable motion:
1) Define “correct use” (Optimal Paths)
By module and role. Keep them versioned.
Examples:
Purchase → Receipt → Putaway (move received items to storage bins) → Stock
Sales Order → Invoice → Payment
2) Segment your cohorts
Role (power users vs operators vs managers)
Team/site (Warehouse A vs B; EU vs US)
Tenure (new vs experienced).
3) Track four core signals
Coverage - % of sessions/users touching a flow
Completion - % finishing successfully
Hesitation - pauses/loops/retries at a step (e.g., Validate, Confirm, Post)
Workarounds - leaving the flow (export → spreadsheet → re-import) to “make it work”
4) Run a weekly adoption review (30-min prep → 30-min call)
Before the call: sort by coverage × hesitation × completion drop; pick top 2–3 flows; assign likely cause: bug / UX-process / knowledge; propose an intervention.
On the call: show what happened, who’s affected, why, and what we’ll do; confirm owners & timelines.
5) Match the fix to the cause
Bug → ticket with repro + before/after impact
UX / process → simplify steps, clarify microcopy, remove dead-ends
Knowledge → targeted training for named users on named steps (don’t invite 50 people)
6) Close the loop next week
Re-check the same flow: hesitation down? completion up? coverage back on path? If not, revisit the cause.
If you’re starting from zero, a clean spreadsheet beats a stack of meeting notes: flow/step, module, role, completion flag, time-to-complete, hesitation proxy, workaround tag, user/session counts.
What to look for each week (signals that matter)
Workflow drifts: skipping, backtracking, or long detours in core flows
Hesitation spikes: pause → re-try → hover-backtrack on steps like Validate / Confirm / Post
Dead-ends & rage clicks: repeat clicks on disabled/blocked elements
Workarounds: leaving native flows to “hack” completion elsewhere
Outlier time-to-complete: steps or cohorts much slower than peers
Form friction & errors: repeated corrections/validation failures on the same fields
Cohort concentration: specific roles/sites disproportionately affected
Triage → Intervention → Proof. That’s the loop.
If you want to compress the time: where Autoplay helps
Use the playbook above with any stack. Autoplay just makes it faster and less guessy by turning raw usage into actionable signals per module, per flow, per cohort:
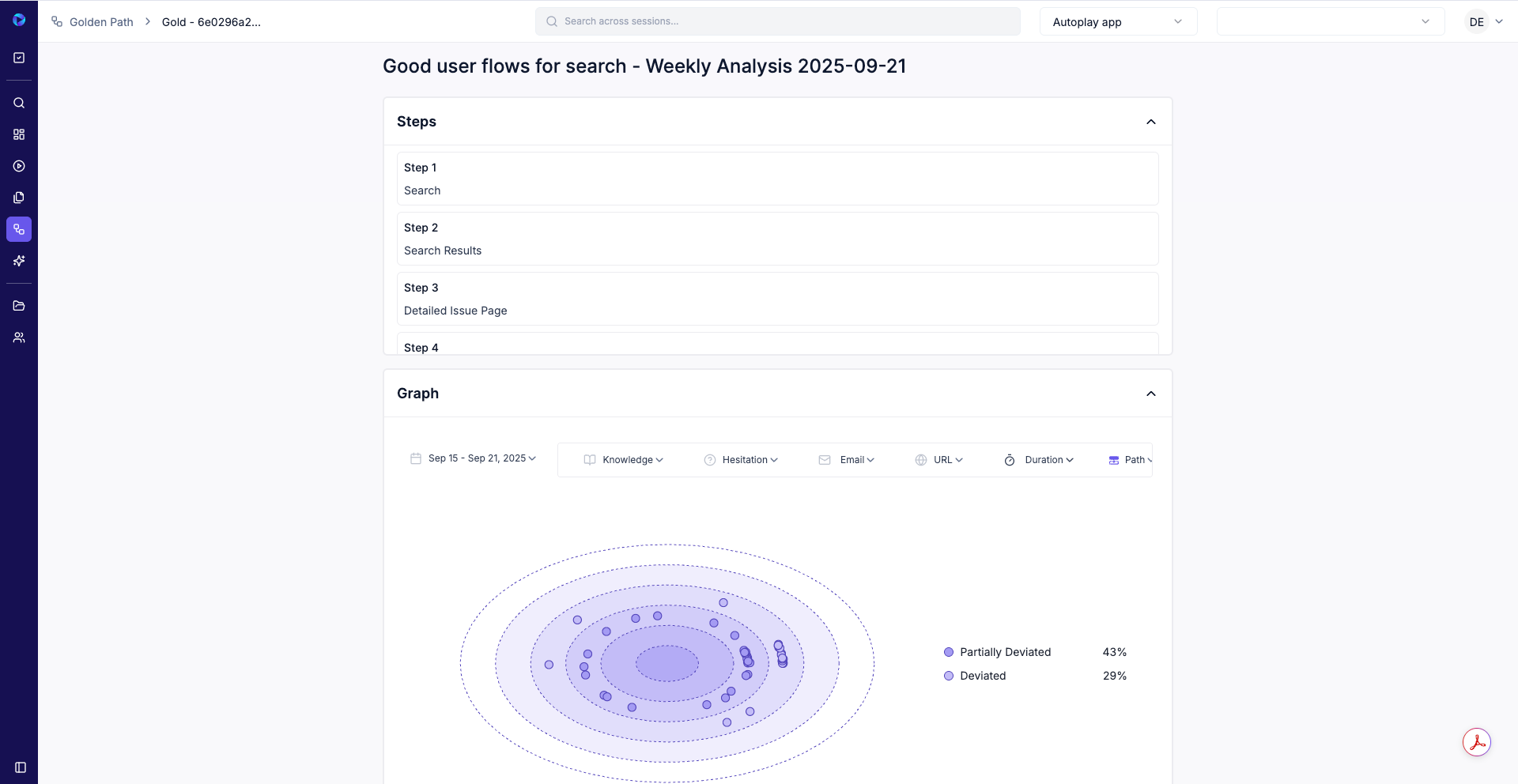
Issue Dashboard (weekly starting point): automatically surfaces top friction patterns by module/flow/cohort with cluster stats (e.g., Sessions: 68 · Coverage: 32.5% · Unique Users: 3 · Hesitation Score: 29).
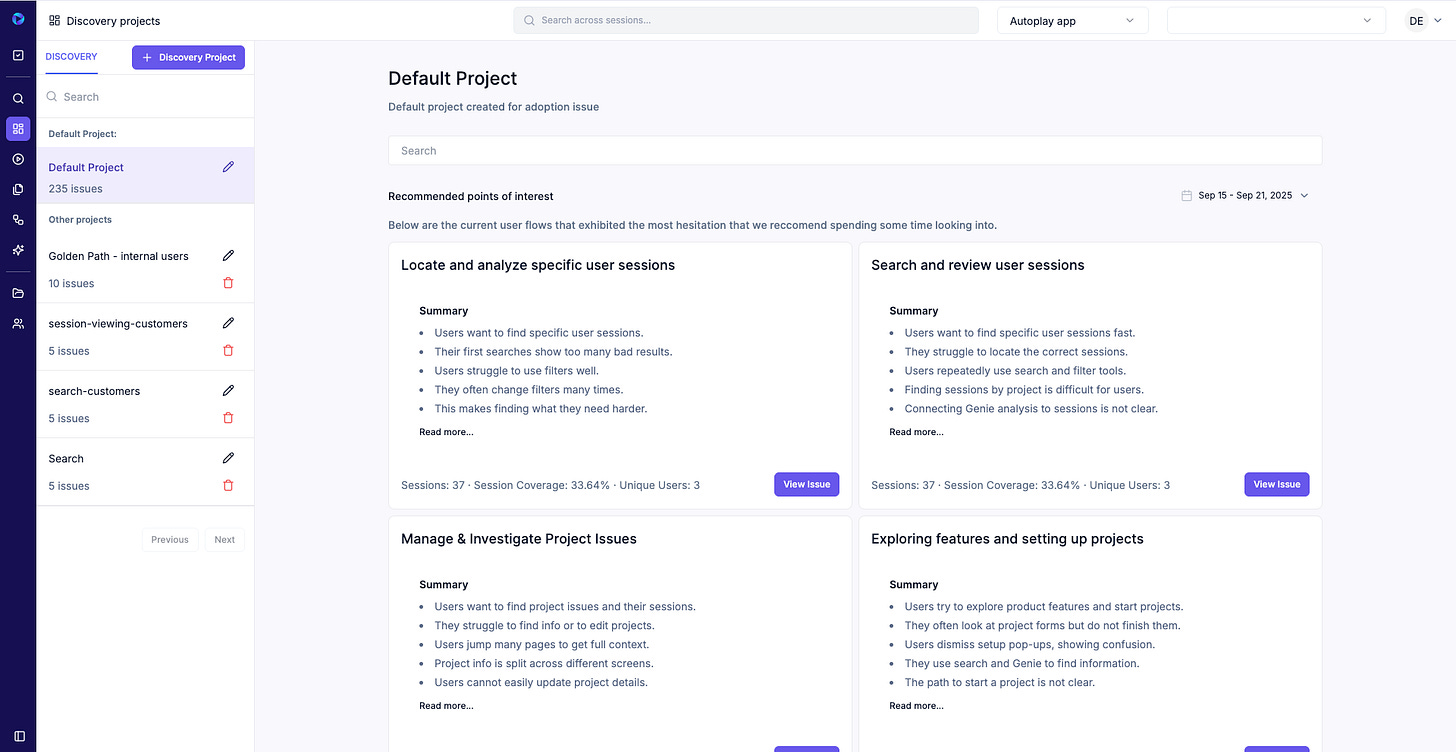
Golden Paths: define once; see exactly where users deviate or hesitate.
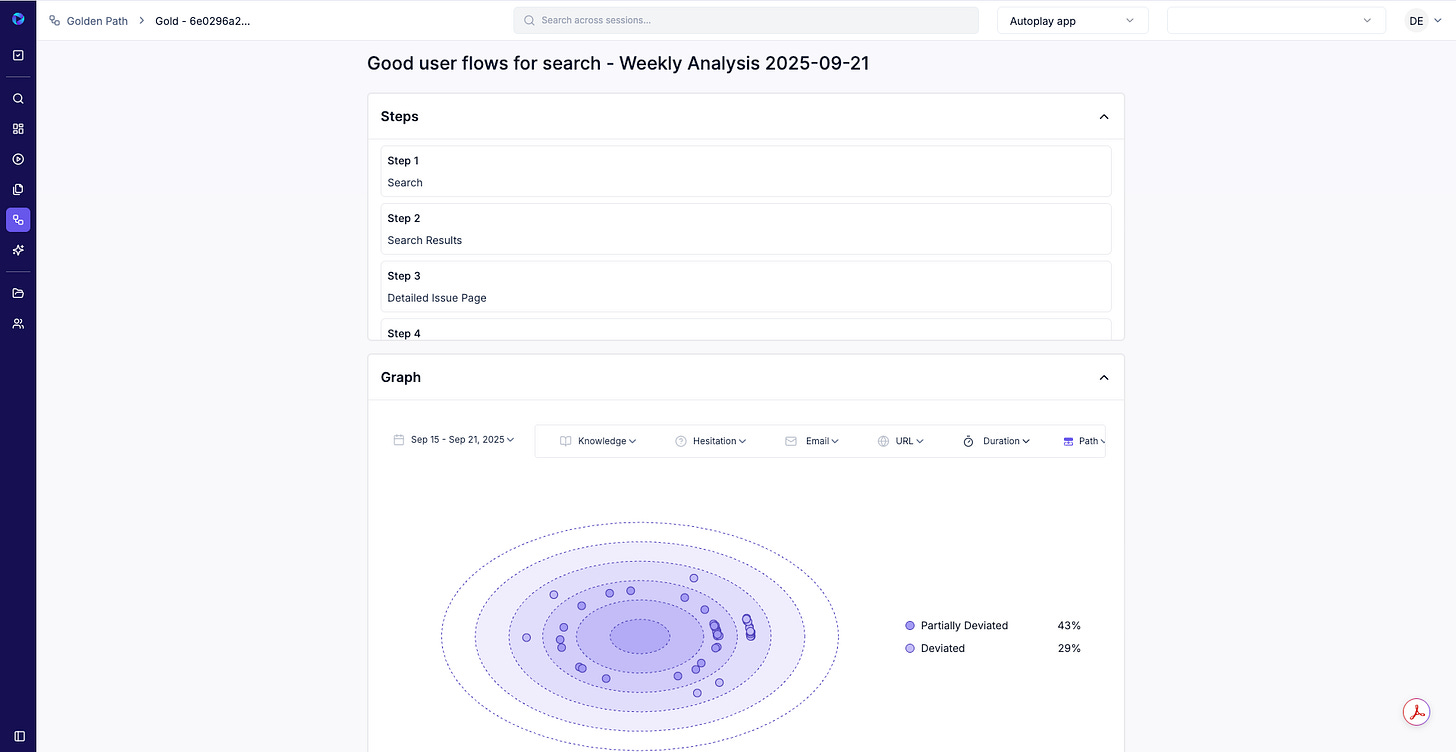
Intent / knowledge / hesitation: UI-aware analysis of what users tried to do, where they got stuck, and why (bug vs UX/process vs knowledge).
Clusters, not one-offs: fix patterns instead of chasing individual replays.
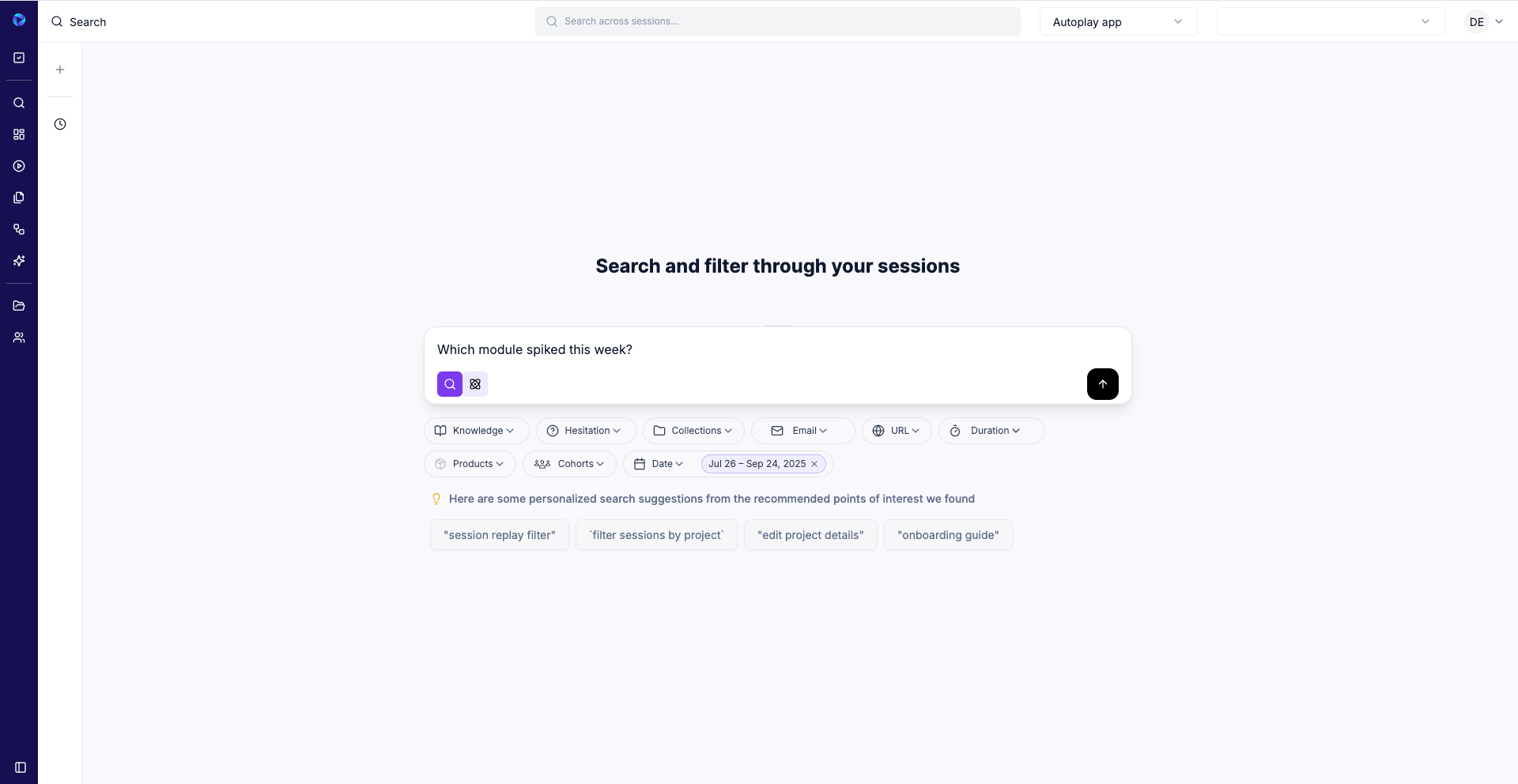
Agentic Q&A (Perplexity Flow): ask, “Which module spiked this week?” “Bug or knowledge gap?” “Which power users are blocked?” and get scoped answers with evidence.
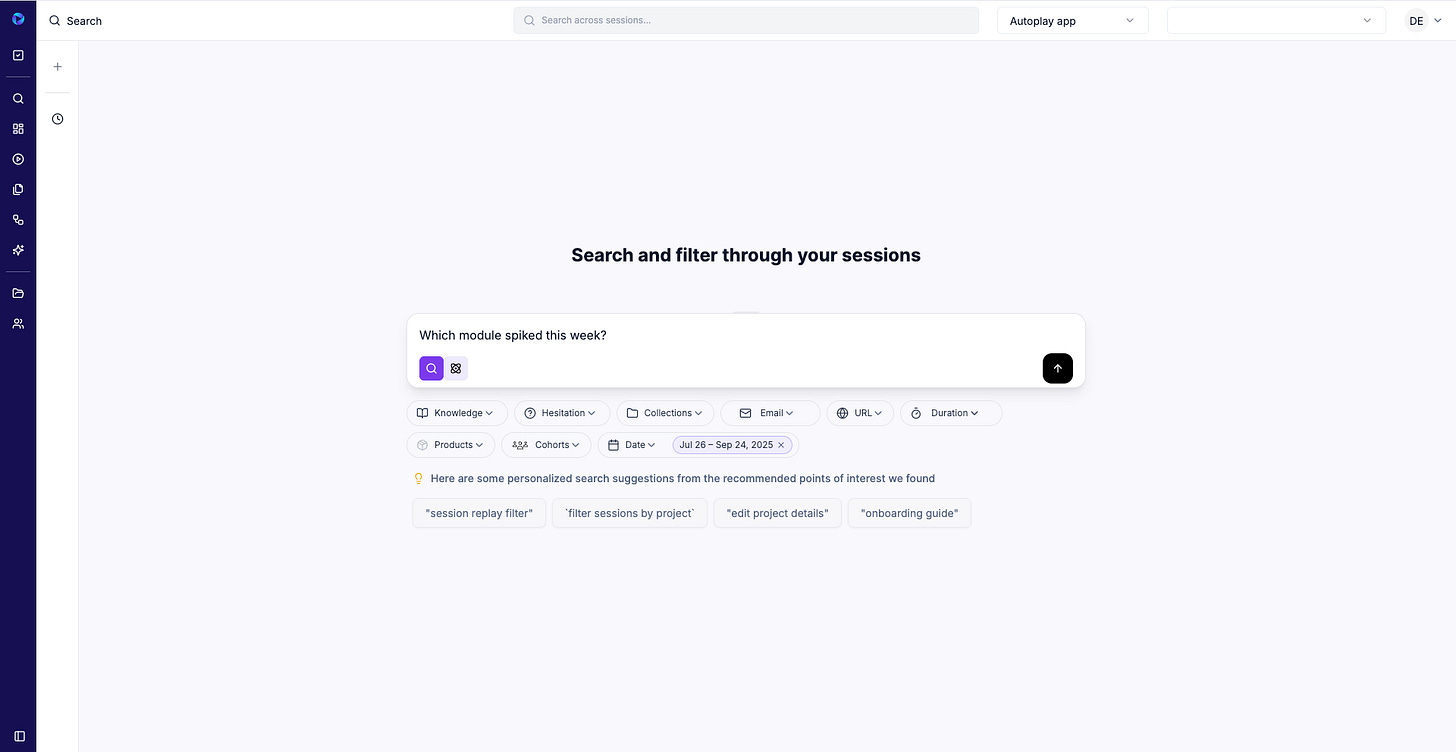
Real-time chat assist: when someone hovers/loops/asks the bot, Autoplay inspects the prior interactions, matches similar successful sessions, and guides them through Odoo’s UI in context - proactive, not generic.
What a better weekly actually looks like
30 minutes before the call:
Open the Issue Dashboard → review the top 3 clusters by coverage.
Note high-hesitation modules (e.g., Inventory > Stock Moves).
Ask: “What’s the likely cause for Cluster #1?”
→ Knowledge gap in Putaway for warehouse power users; repeated hover-backtrack on Validate.Ask: “Any bug signatures?”
→ Compare before/after windows; flag real defects if present.Decide the intervention:
Bug (ticket)
UX (microcopy/flow tweak)
Knowledge (targeted training for named cohorts).
Walk into the call with:
The issues that matter
The users affected
The cause
The recommended fix.
One weekly, not two. Less guessing, more outcomes.
Why this matters to Odoo partners
Proactive retention: show up with evidence, not anecdotes - what broke, where, for whom.
Targeted training (instant ROI): identify which users are struggling and on which step inside which module; don’t pull everyone into a generic session.
Fewer internal meetings: replace “let’s ask everyone” with “here’s what’s happening,” plus named cohorts to address.
Less bias, more truth: behavior + intent beats manager summaries and survey guesswork.
Clear accountability: tie issues to modules, flows, and specific users; ship the fix; close the loop next week.
A quick scenario
Observation: Inventory shows 32% of sessions deviating at Putaway (moving received items into their storage bins).
Cause: No defect. Users hover → backtrack on Validate. Knowledge gap.
Action: 30-minute micro-training for warehouse power users + inline copy tweak.
Follow-up: Next week, hesitation drops; completion rises. Done.
(Compare that to two calls of “what’s not working?” plus a survey no one reads.)
In short:
Weekly calls and surveys might keep the relationship warm - but they won’t show you who’s stuck, where, or why. Adoption is the real metric, and you can’t fix what you can’t see. The partners who win are the ones who move faster, with precision. Not more meetings - just better ones, built on evidence.